Introducing CUB: Theta's Computer Use Benchmark
May 15, 2025
Introducing CUB: Theta's
Computer Use Benchmark
Manus
OpenAI CUA
Claude Computer Use*
Browser Use*
Gemini 2.5 Pro
We're excited to announce CUB, a first-of-its-kind benchmark for computer and browser use agents. With 106 end-to-end workflows across consumer, construction, finance, healthcare, marketing, sales, and supply chain, CUB is the most diverse and representative benchmark for evaluating computer and browser use agents. We've worked with accountants, investment bankers, doctors, and other experts to create high-quality domain-specific tasks. These tasks involve real-world workflows and software tools across these industries, with synthetic versions of enterprise platforms such as SAP and CapIQ.
We show an initial set of results below:

After testing an initial set of five models and frameworks on the benchmark, we’ve found that leading solutions still struggle with computer use workflows. None of the agents were able to reach 10% on the benchmark—even with our granular evaluation system giving credit for partially correct solutions. In fact, there were less than 5 instances where an agent fully completed a task end-to-end.
We developed this benchmark with a few key design choices in mind. Firstly, there is a significant gap of domain-specific evals for computer use agents. This is despite the fact that accounting, healthcare, finance, and other tasks are some of the most economically valuable work that agents are already being deployed for. Evaluating agents on end-to-end workflows is uniquely important because it requires agents to demonstrate proficiency in the following areas, each of which is critical in real-world tasks:
- Long-sequence memory and instruction following
- Coordination across multiple software applications
- Maintaining action coherence and reliability when performing repetitive tasks
- Interacting with unfamiliar and unintuitive domain-specific interfaces
Alongside the benchmark, we’re also introducing our computer environment infrastructure for effective evaluation and post-training at scale. Optimized parallelization and VM snapshotting allows for faster evals and more data. Our environments support black-box agentic systems, a rich action space, and both browser and desktop-based configurations.
We're looking forward to testing more models and frameworks on CUB. Please reach out to founders@thetasoftware.ai for more details. Some sample tasks are listed below.
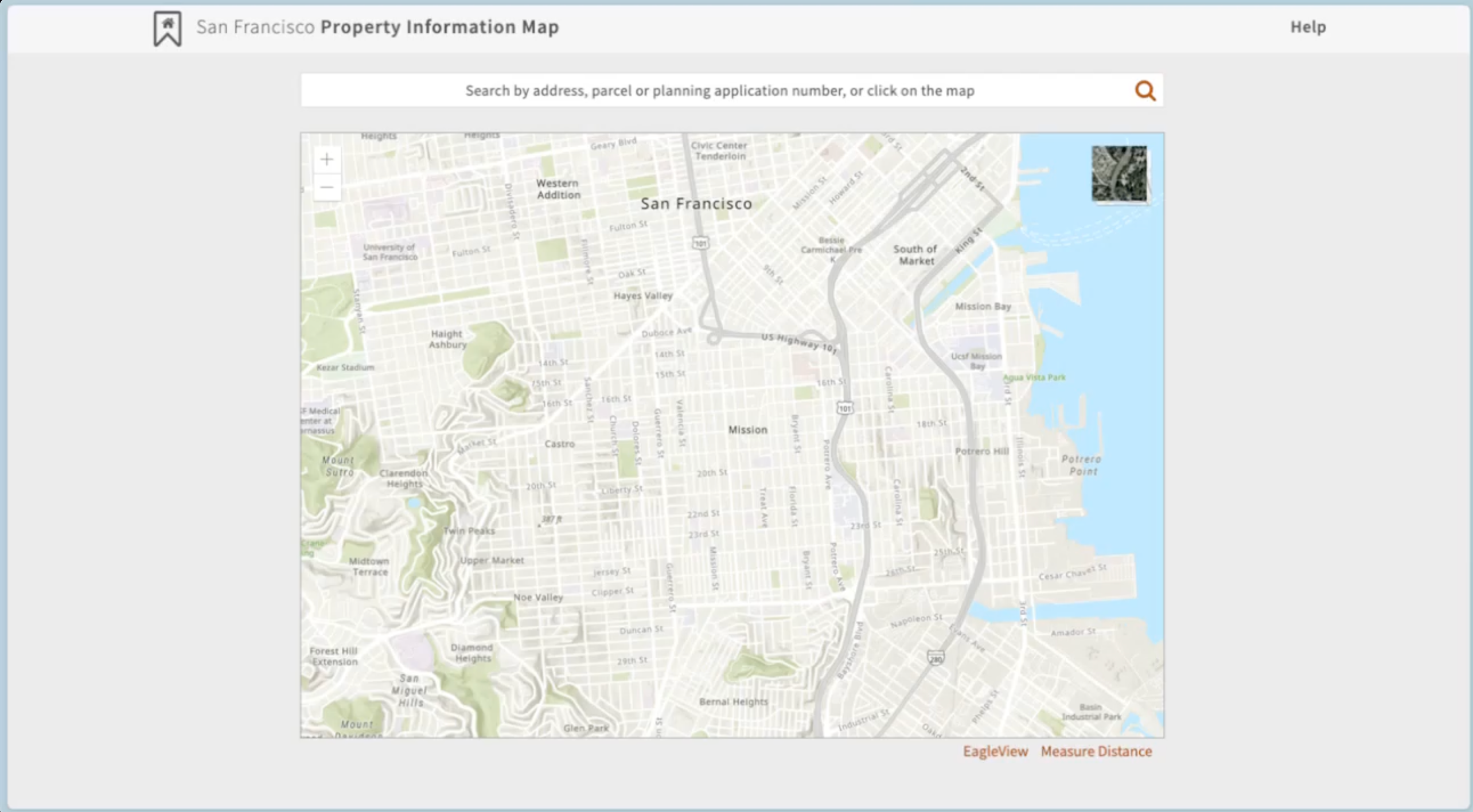
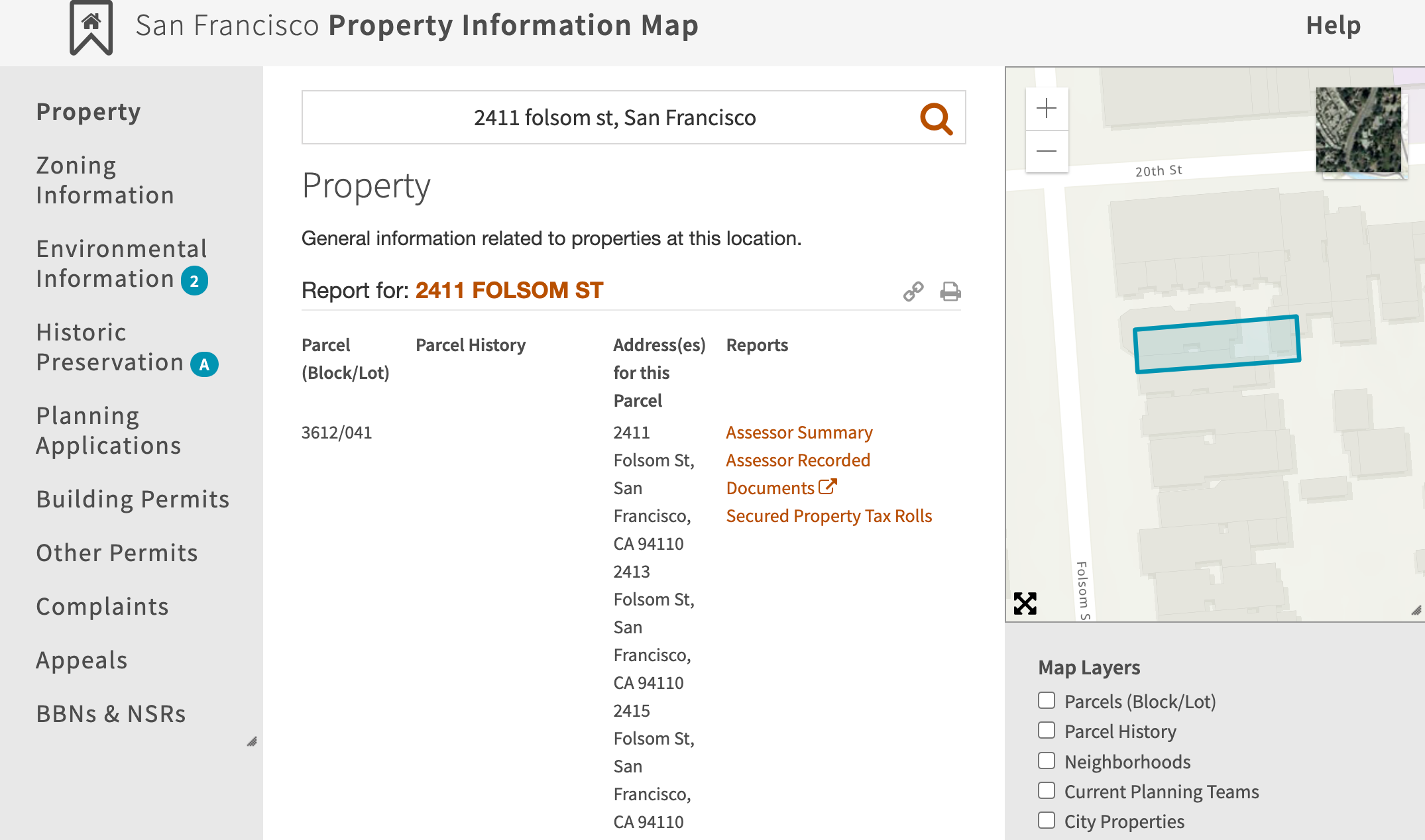
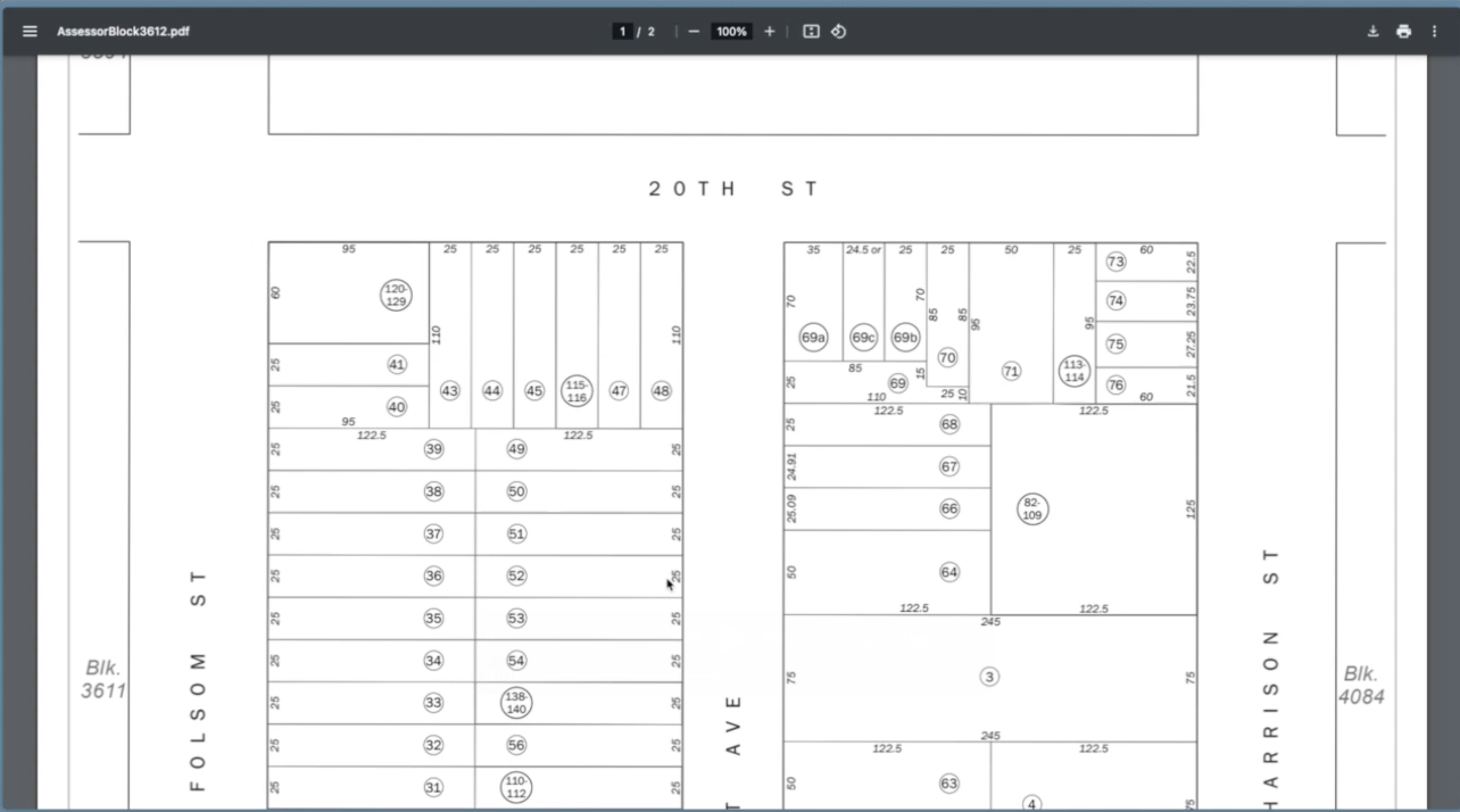
The agent is tasked with calculating the square footage of a property using publicly available block maps. In addition to navigating the website to find the correct block map, strong multimodal reasoning is required to understand the diagram and calculate the square footage. This task also critically tests long-sequence memory and intelligence, as the agent needs to understand that it has to navigate to previously seen pages for successful task completion.



For this task, the agent is provided with a patient document from a recent eye exam and must enter pertinent information into an electronic health record (EHR) platform. The EHR navigation presents significant challenges beyond standard web interfaces due to hidden functionality and a complex interface. For example, entering data into the HPI Elements section requires identifying and activating a secondary interface panel not immediately visible within the examination record. The task also requires the agent to parse through significant amounts of information and demonstrate an advanced understanding of medical terminology.


